



排序

Debian环境中Hadoop性能调优实践
提升Debian环境下Hadoop集群性能,需要多方面协同优化,涵盖硬件资源配置、操作系统参数调整、JVM参数设置、Hadoop配置参数微调、数据分区策略、压缩技术应用以及持续监控和动态调整等环节。以...

Hadoop在Linux上的数据存储方式有哪些
Hadoop在Linux上的核心数据存储方法依托于其分布式文件系统(HDFS)。以下是Hadoop在Linux上数据存储方式的具体描述: HDFS架构解析 数据分块(Block):Hadoop的数据以块的形式储存在HDFS里,...
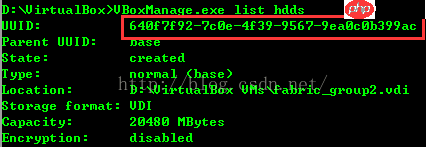
VirtualBox下Linux虚机扩容
节后上班第一天,按照计划开始搭建hadoop和hive实验环境,但尚未开始安装就遇到了一个难题:jdk安装包解压时提示空间不足。原先的四个虚拟机,每台分配了8g内存,其中根文件系统占用6g,完成fab...

如何实现Python数据的近实时处理?流处理架构
python实现近实时数据处理的核心在于转向流处理架构,其关键组件包括数据摄入层(如kafka)、流处理引擎(如faust、pyspark structured streaming、pyflink)、数据存储层(如cassandra、mongod...

Debian Hadoop 权限怎样设置
在Debian系统中配置Hadoop权限主要包括以下几个方面: 用户与用户组管理 使用 useradd、userdel 和 usermod 等命令进行用户账户的创建、删除和修改。 使用 groupadd、groupdel 和 groupmod 命令...

hadoop的核心是分布式文件系统hdfs和什么?
hadoop的核心是分布式文件系统hdfs和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了...

如何在CentOS上监控HDFS
在centos上监控hdfs(hadoop分布式文件系统)可以通过多种方式实现,包括使用hadoop自带的命令行工具、web界面以及第三方监控工具。以下是一些常用的方法: Hadoop命令行工具: hdfs dfsadmin -r...

Python数据仓库 Python大数据存储解决方案
python在数据仓库和大数据存储中主要作为连接和处理工具。1. 它用于etl流程,包括从数据库、api等来源提取数据;2. 使用pandas或pyspark进行数据清洗和转换;3. 将处理后的数据写入目标系统如po...

深度优化数据库性能:Linux 内核参数调整解析
数据库服务器性能的优化是每个it团队关注的焦点之一。除了数据库引擎的优化之外,合理调整操作系统的内核参数也是提高数据库性能的关键。本文将解析一些常见的 linux 内核参数,以及它们在数据...

Debian Hadoop 应用怎样开发
在Debian操作系统上进行Hadoop应用的开发,需按照以下流程操作: 1. 安装Java运行环境 由于Hadoop基于Java语言编写,因此首要任务是在Debian系统中安装Java。sudo apt update sudo apt install ...