



排序

大厂 SQL 是什么样的?从简单题目到复杂图形化,剖析其核心应用场景
大厂的sql远不止增删改查,其本质区别在于面对的是海量数据、复杂业务和高并发场景下的系统性挑战。1. 数据量级上,大厂处理pb甚至eb级数据,需依赖分区表、列式存储、索引策略及分布式架构(如...

基础 SQL 是什么?入门必知 基础 SQL 在数据库学习中的核心概念与应用优势
sql的核心概念包括:1. 数据定义语言(ddl),用于创建、修改和删除表结构,如create table、alter table和drop table;2. 数据操作语言(dml),用于查询、插入、更新和删除数据,核心命令为se...

Hive-sql和sql的区别是什么?
区别:1、Hive-sql不支持等值连接,而sql支持;2、Hive-sql不支持“Insert into 表 Values()”、UPDATA、DELETE操作,而sql支持;3、Hive-sql不支持事务,而sql支持。 总体来说hiveSQL与SQL基本...

MySQL分表查询如何高效处理多字段组合条件?
优化MySQL分表查询:多字段组合条件下的高效方案 大型应用数据库常常面临数据量膨胀的问题,分表是提升查询效率的常用策略。本文针对基于哈希分表策略的多字段组合查询条件下的高效访问问题,提...

Java开发者必会的大数据工具和框架有哪些
1、mongodb——最受欢迎的,跨平台的,面向文档的数据库。 MongoDB是一个基于分布式文件存储的数据库,使用C++语言编写。旨在为Web应用提供可扩展的高性能数据存储解决方案。应用性能高低依赖于...

Debian系统中Hadoop日志管理
高效管理Debian系统中的Hadoop日志,需要掌握以下核心方法和工具: 一、日志集中管理 启用日志聚合功能: 在Hadoop的yarn-site.xml配置文件中,将yarn.log-aggregation-enable属性设置为true。 ...

navicat能连接hive么
Navicat连接hive的步骤: 第一步:win下安装好mysql。 第二步:win下安装Navicat。 第三步:启动hadoop集群,启动hive。 第四步:Navicat连接hive。 在第四步中需先配置ssh,然后配置常规属性,...
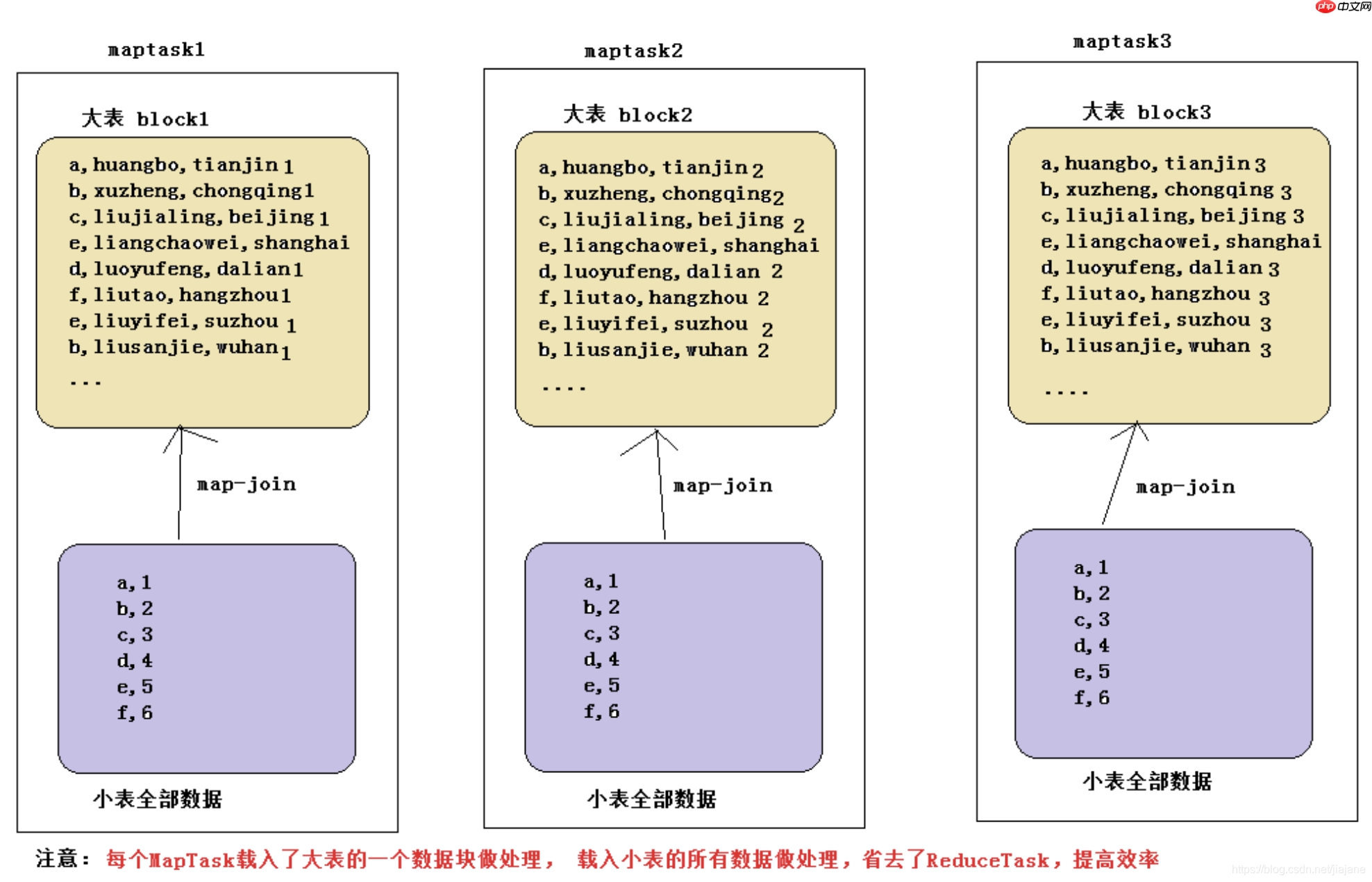
【Hive】hive 数据倾斜、优化策略、hive执行过程、垃圾回收
1. 数据倾斜 1.1 什么是数据倾斜?由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点Hadoop 框架的特性代码语言:txt复制- 不怕数据大,怕数据倾斜- Jobs 数比较多的作业运行效率...

如何利用CentOS HDFS进行大数据分析
在centos系统上利用hdfs(hadoop分布式文件系统)进行大数据分析,需要遵循以下步骤: 一、搭建Hadoop集群 安装依赖项: 安装CentOS系统必要的依赖包,例如gcc、openssh-clients等。 配置JDK: 安...

Debian如何整合Hadoop与其他服务
在Debian上将Hadoop与其他服务进行整合通常需要遵循以下步骤: 安装Java环境: Hadoop依赖于Java环境,确保安装Java 8或更高版本。你可以使用以下命令来安装OpenJDK 8: sudo apt update sudo a...