



排序
【Hive】hive 数据倾斜、优化策略、hive执行过程、垃圾回收
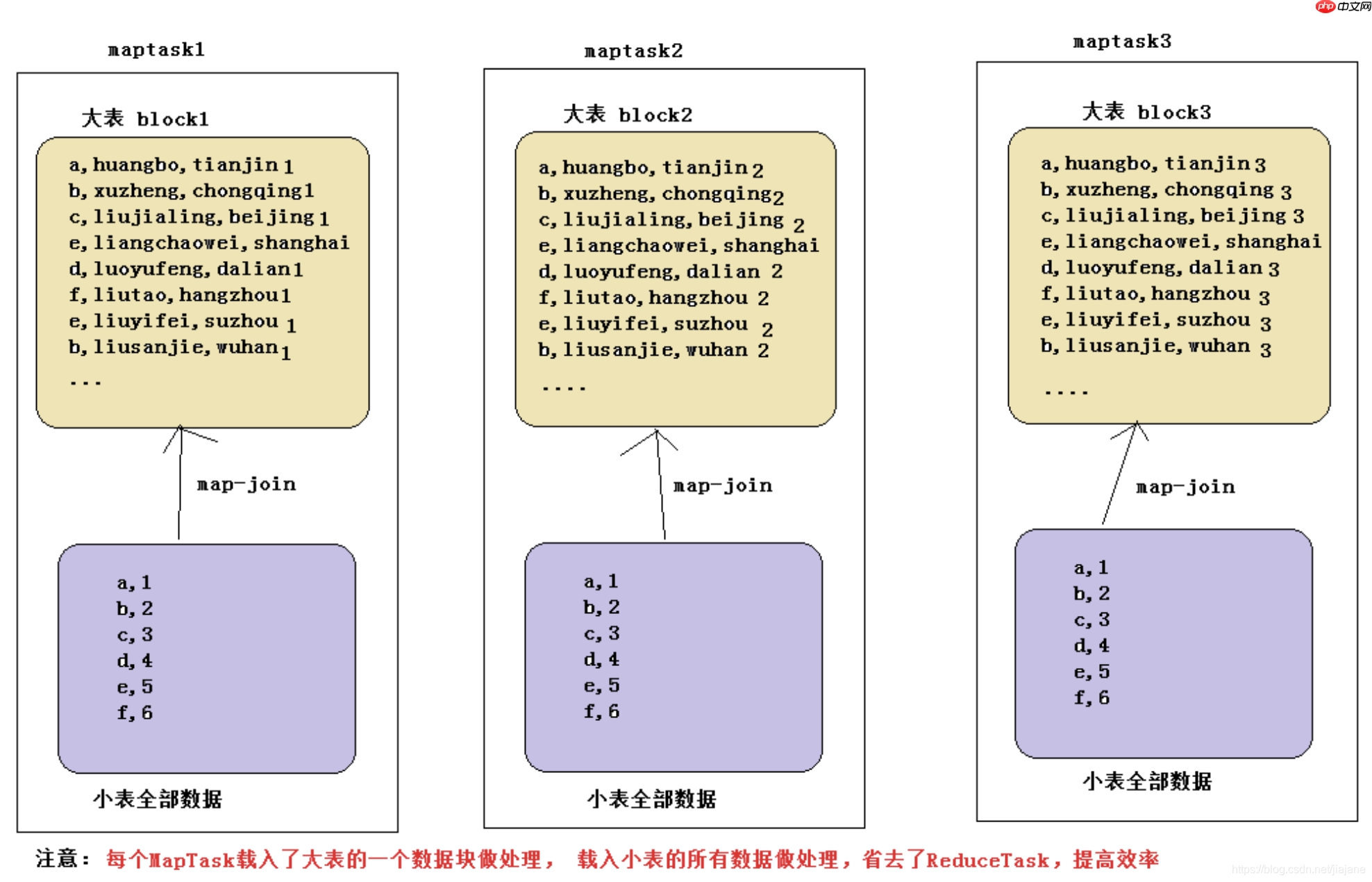
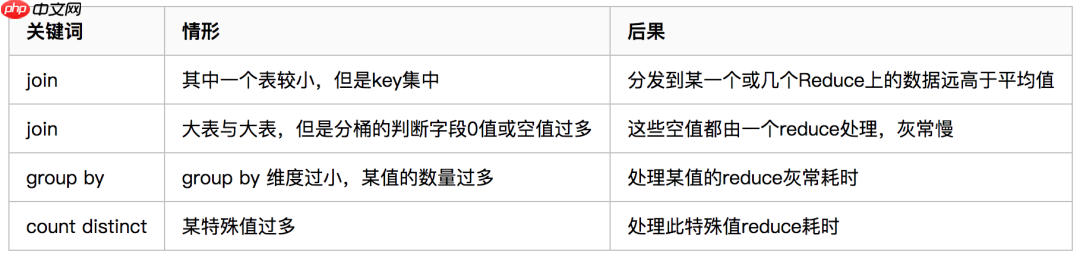
1. 数据倾斜 1.1 什么是数据倾斜?由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点Hadoop 框架的特性代码语言:txt复制- 不怕数据大,怕数据倾斜- Jobs 数比较多的作业运行效率...
万文Hive常用参数调优及优化(建议收藏)
1. limit限制调整 一般情况下,Limit语句还是需要执行整个查询语句,然后再返回部分结果。 有一个配置属性可以开启,避免这种情况---对数据源进行抽样。 hive.limit.optimize.enable=true --- ...

数据清洗管道中:怎样实现“跳过错误记录+生成错误报告”双机制?
在数据清洗管道中实现“跳过错误记录+生成错误报告”双机制的方法是:1. 在每个关键步骤使用 try-except 块捕获异常,确保流程不中断;2. 在 except 块中记录错误信息至日志文件或数据库;3. 通...

如何在CentOS上监控HDFS
在centos上监控hdfs(hadoop分布式文件系统)可以通过多种方式实现,包括使用hadoop自带的命令行工具、web界面以及第三方监控工具。以下是一些常用的方法: Hadoop命令行工具: hdfs dfsadmin -r...

窗口函数RANK()/ROW_NUMBER():如何实现分组排名而不影响查询性能?
要在使用sql进行分组排名时避免拖慢查询速度,关键在于合理使用窗口函数与索引。1. 使用partition by和order by实现分组排名,优先根据需求选择row_number()或rank()函数;2. 在group_id和score...

Debian Hadoop 权限怎样设置
在Debian系统中配置Hadoop权限主要包括以下几个方面: 用户与用户组管理 使用 useradd、userdel 和 usermod 等命令进行用户账户的创建、删除和修改。 使用 groupadd、groupdel 和 groupmod 命令...

Debian Hadoop 应用怎样开发
在Debian操作系统上进行Hadoop应用的开发,需按照以下流程操作: 1. 安装Java运行环境 由于Hadoop基于Java语言编写,因此首要任务是在Debian系统中安装Java。sudo apt update sudo apt install ...

Hadoop在Linux上的数据存储方式有哪些
Hadoop在Linux上的核心数据存储方法依托于其分布式文件系统(HDFS)。以下是Hadoop在Linux上数据存储方式的具体描述: HDFS架构解析 数据分块(Block):Hadoop的数据以块的形式储存在HDFS里,...

HDFS与其他存储系统如何集成
HDFS(Hadoop分布式文件系统)是大数据技术的重要组成部分,它能够与其他多种存储系统整合,以适应多样化的应用场景。以下是HDFS与其他存储系统整合的主要形式: HDFS与对象存储的结合 对象存储...

HDFS如何与其他大数据技术集成
HDFS(Hadoop Distributed File System)作为Hadoop生态体系中的关键部分,能够与多种大数据技术如Spark、Hive、HBase等无缝结合,打造高性能的数据处理和分析平台。以下是HDFS与这些工具的整合...