



排序

Java怎样处理气象大数据?Spark并行计算
java处理气象大数据结合spark的并行计算能力,是一种高效且成熟的方案。其核心在于构建基于java和spark的分布式处理管道,流程包括:1.利用java解析netcdf、grib等复杂格式数据;2.将数据转换为...

SQL语言如何处理数据倾斜问题 SQL语言在大数据环境中的负载均衡方案
数据倾斜对sql查询性能的影响是灾难性的,主要表现为查询耗时显著增加、出现长尾任务、内存溢出(oom)、网络i/o瓶颈以及集群资源利用率不均。1. 查询耗时剧增:因倾斜键导致部分节点处理数据量...

Linux Kafka如何与其他中间件协同工作
Linux Kafka,作为一款高性能分布式流处理平台,在构建实时数据流应用方面表现卓越。其与其他中间件的集成,扩展了其应用范围,提升了数据处理能力。以下是一些常见的集成方案及应用场景: Kafk...

CentOS HDFS与Spark如何协同工作
在centos上,hadoop分布式文件系统(hdfs)与apache spark可以协同工作,以实现高效的数据处理和分析。以下是实现这一集成的详细步骤: 1. 安装和配置HDFS 安装Java:确保系统已安装合适的JDK版...
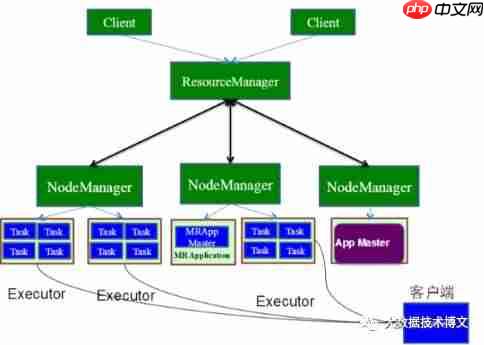
Spark专题系列(三):Spark运行模式
一:spark运行模式分类 Spark的运行模式可以分为三类: 本地模式(local),适用于演示或测试,通常在Shell命令行中运行。 独立模式(standalone),可以在一个集群中独立运行,利用Spark自身的...

PySpark foreachPartition 传递额外参数的正确方法
PySpark foreachPartition 传递额外参数的正确方法 foreachPartition 是 PySpark DataFrame API 中一个强大的方法,它允许我们对 DataFrame 的每个分区执行自定义操作。然而,foreachPartition ...
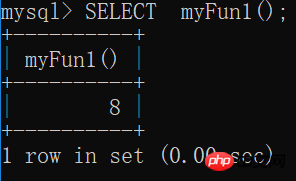
Mysql函数 的相关讲解
含义:一组预先编译好的SQL语句的集合,可以理解成批处理语句作用: 提高代码的重用性 简化操作 减少了编译次数并且减少了和数据库服务器的连接次数,提高了效率 和存储过程的区别:存储过程:...

Linux环境下Kafka数据备份策略是什么
在linux环境下,kafka的数据备份策略主要包括以下几种方式: 副本机制 定义:通过增加主题的副本因子,可以增强消息的可靠性。在副本因子为n的情况下,通常可以容忍n-1个副本故障而不丢失数据。...

窗口函数RANK()/ROW_NUMBER():如何实现分组排名而不影响查询性能?
要在使用sql进行分组排名时避免拖慢查询速度,关键在于合理使用窗口函数与索引。1. 使用partition by和order by实现分组排名,优先根据需求选择row_number()或rank()函数;2. 在group_id和score...

如何基于Java构建数据可视化平台 Java图表展示模块盈利实现
核心技术栈选择包括spring boot(后端框架)、jpa/mybatis(数据访问)、mongodb/elasticsearch(补充存储)、kafka/rabbitmq(消息队列)、spark/flink(大数据处理)、react/vue(前端框架)...