



排序

apache spark 是什么
Spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速。Spark非常小巧玲珑,由加州伯克利大学AMP实验室的Matei为主的小团队所开发。使用的语言是Scala,项目的core部分的代...

Python中如何实现词频统计?
在python中实现词频统计可以通过以下步骤进行:1. 使用字典统计词频,2. 改进代码处理大小写和标点符号,3. 使用生成器处理大文件,4. 过滤停用词,5. 优化性能和扩展性。每个步骤都提供了不同...

java主要是干嘛的 Java在实际开发中的主要用途解析
java 主要用于构建桌面应用、移动应用、企业级解决方案和大数据处理。1. 企业级应用:通过 java ee 支持复杂应用,如银行系统。2. web 开发:使用 spring、hibernate 简化开发,spring boot 快...

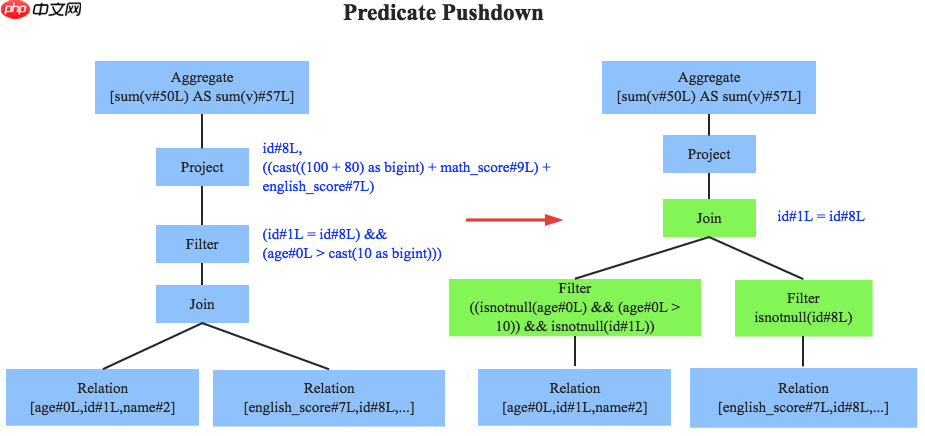
PHP怎么实现数据自动聚合统计 数据聚合统计方法详解
数据自动聚合统计可通过多种方法实现,核心方法包括1. 基于sql的聚合查询:使用count、sum等函数结合group by对数据库数据进行高效汇总;2. php内存聚合:适用于小数据量或复杂逻辑,在php中遍...

如何用Python构建自动化异常检测系统?完整流程
构建自动化异常检测系统需经历数据收集与清洗、特征工程、模型选择与训练、阈值设定与评估、部署与自动化、监控与反馈等六个阶段。1. 数据收集与清洗:整合多源数据,处理缺失值与异常值,统一...

vscode如何执行ada代码 vscode航天级语言开发指南
要在#%#$#%@%@%$#%$#%#%#$%@_e2fc++805085e25c9761616c00e065bfe8中执行ada代码并用于航天级语言开发,需集成gnat编译器和语言服务。1. 安装gnat编译器并配置path环境变量;2. 安装“ada langua...

数据清洗管道中:怎样实现“跳过错误记录+生成错误报告”双机制?
在数据清洗管道中实现“跳过错误记录+生成错误报告”双机制的方法是:1. 在每个关键步骤使用 try-except 块捕获异常,确保流程不中断;2. 在 except 块中记录错误信息至日志文件或数据库;3. 通...

Linux Kafka的运维管理有哪些挑战
Linux Kafka的运维管理面临着多个挑战,主要包括以下几个方面: 硬件与资源管理 硬件性能要求高: Kafka对CPU、内存和磁盘I/O有较高要求。 需要监控和优化硬件资源以避免瓶颈。 存储扩展性: Ka...
浅谈SQL执行计划优化(GBase8s篇)
在日常开发过程中,优化sql查询始终是一个具有挑战性的任务。俗话说,工欲善其事,必先利其器。今天,我们将探讨如何查看gbase8s的执行计划以及有哪些优化手段。 执行计划优化分为基于规则的优...

实现Oracle数据库与Kafka的数据交互和同步
实现oracle数据库与kafka的数据同步需要以下步骤:1)使用oracle goldengate或cdc捕获oracle数据库变化;2)通过kafka connect将数据转换并发送到kafka;3)使用kafka消费者进行数据消费和处理...