



排序

怎样用Python制作词云图?jieba分词与wordcloud可视化指南
用python制作词云图的步骤如下:1. 安装jieba、wordcloud和matplotlib库;2. 使用jieba进行中文分词并过滤停用词;3. 利用wordcloud生成词云,指定字体路径等参数;4. 通过matplotlib显示词云图...

PHP和MySQL开发大数据处理系统的思路
php和mysql在大数据处理中不是首选,但在特定场景下仍能发挥作用。1) 数据分片:按业务逻辑分布数据。2) 读写分离:使用主从复制技术。3) 缓存机制:利用redis或memcached减少数据库访问。4) 异...

数据清洗管道中:怎样实现“跳过错误记录+生成错误报告”双机制?
在数据清洗管道中实现“跳过错误记录+生成错误报告”双机制的方法是:1. 在每个关键步骤使用 try-except 块捕获异常,确保流程不中断;2. 在 except 块中记录错误信息至日志文件或数据库;3. 通...
分分钟搞定各种应用类型在k8s上的运行配置!
在kubernetes (k8s) 上运行各种类型的应用是完全可行的。关键在于根据应用的具体需求选择合适的k8s资源类型。以下是如何在k8s上配置不同类型应用的详细指南: 众所周知,Kubernetes(K8S)更适...

SQL表分区实现指南 SQL大数据分表策略
sql表分区和大数据分表均用于解决数据量过大导致的性能瓶颈问题。01. sql表分区是逻辑分割,适用于同一数据库实例内,包括范围、列表、哈希和复合分区等方式,提升查询效率;02. 大数据分表是物...
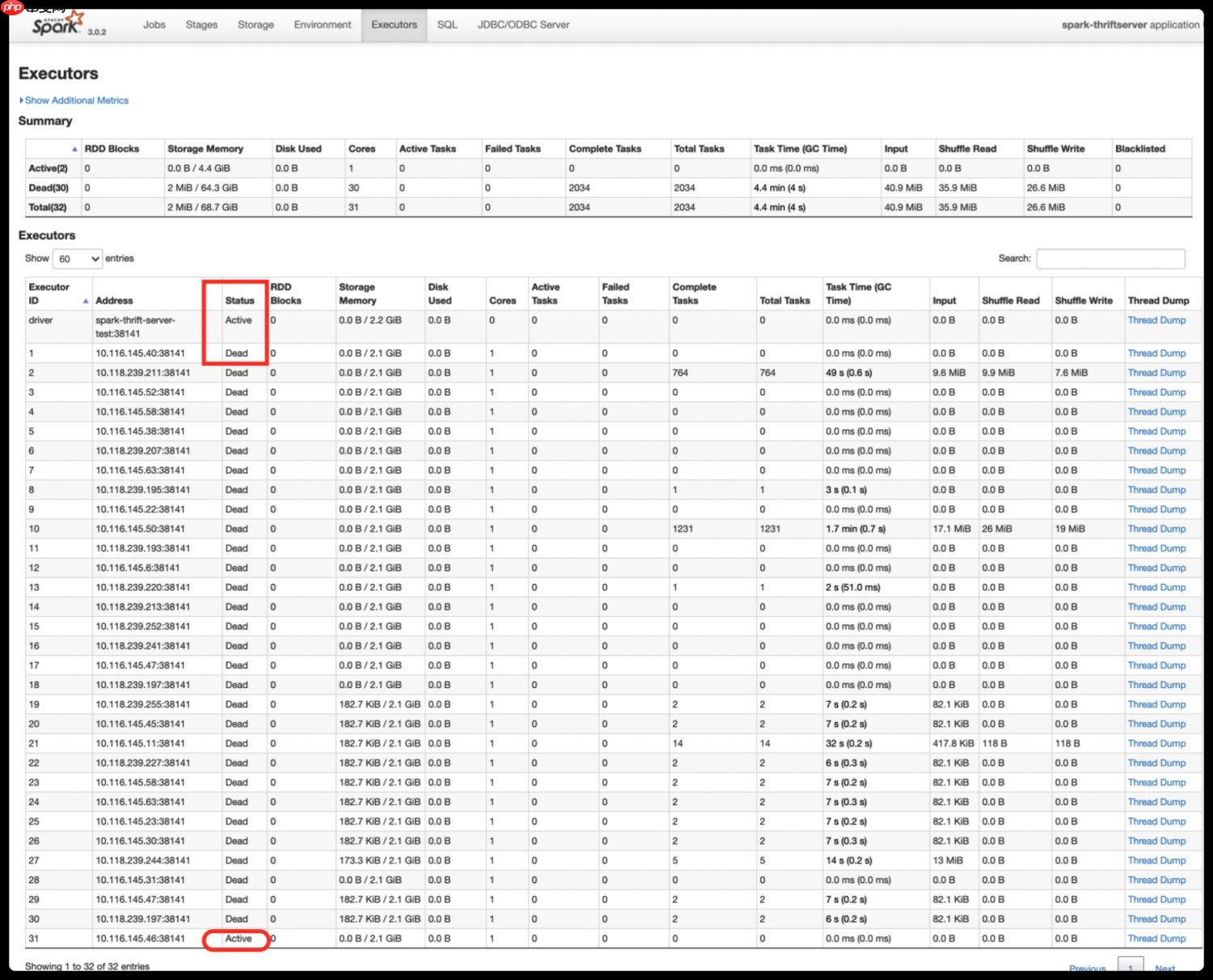
「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
前言 资源是影响 Spark 应用执行效率的一个关键因素。Spark 应用中执行任务的组件是 Executor,通过 spark.executor.instances 参数可以设定 Spark 应用的 Executor 数量。在运行过程中,无论 E...

窗口函数RANK()/ROW_NUMBER():如何实现分组排名而不影响查询性能?
要在使用sql进行分组排名时避免拖慢查询速度,关键在于合理使用窗口函数与索引。1. 使用partition by和order by实现分组排名,优先根据需求选择row_number()或rank()函数;2. 在group_id和score...
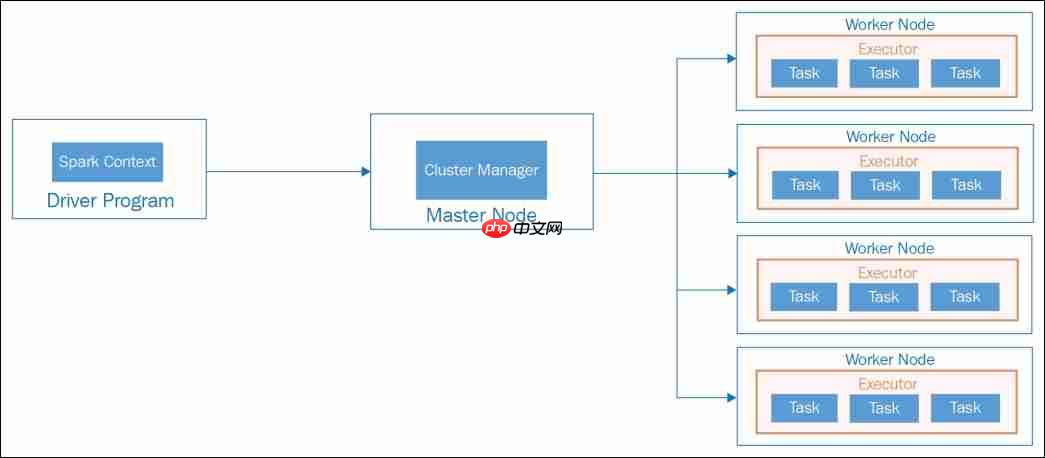
Spark Architecture 系统架构
let's delve into the apache spark architecture, providing a high-level overview and discussing some key software components in detail. High-Level Overview Apache Spark's applicatio...

PHP怎么实现文件秒传功能 基于文件指纹的秒传技术实现
php实现文件秒传的核心在于利用文件指纹技术避免重复上传。1.前端使用javascript(如spark-md5库)计算文件md5或sha1值;2.后端php接收指纹并查询数据库判断是否存在相同指纹文件;3.若存在则直...

Python大数据处理:PySpark入门
pyspark 是 python 在大数据生态中的重要工具,适合处理海量数据。它基于 spark 的分布式计算能力,支持并行处理数十 gb 到 tb 级数据。与 pandas 不同,pyspark 可跨节点分片数据,避免内存限...