



排序

怎样用Python实现数据标注—LabelEncoder编码技巧
labelencoder 是 sklearn.preprocessing 中用于将类别型标签转换为数值型的工具,其核心作用是将文本类别映射为从0开始的整数。使用时需先导入并调用 .fit_transform() 方法完成训练与编码,输...

Python中如何使用sklearn进行机器学习?
使用sklearn进行机器学习的步骤包括:1. 数据预处理,如标准化和处理缺失值;2. 模型选择和训练,使用决策树、随机森林等算法;3. 模型评估和调参,利用交叉验证和网格搜索;4. 处理类别不平衡...

bootstrap抽样在广义线性模型中的应用
bootstrap抽样是一种从原始数据中有放回抽取样本以形成新数据集的重采样技术,用于评估模型参数稳定性、计算置信区间或假设检验。其核心在于通过重复拟合模型直接估计参数变异性,不依赖传统统...

如何使用Python实现数据聚类?KMeans算法
kmeans聚类的核心步骤包括数据预处理、模型训练与结果评估。1. 数据预处理:使用standardscaler对数据进行标准化,消除不同特征量纲的影响;2. 模型训练:通过kmeans类设置n_clusters参数指定簇...

Python怎样进行数据聚类?K-means算法实现
数据聚类在python中常用k-means算法实现,其步骤包括:1.数据准备需标准化处理并清理缺失值;2.使用sklearn.cluster.kmeans进行聚类,设置n_clusters和random_state以获得稳定结果;3.通过肘部...
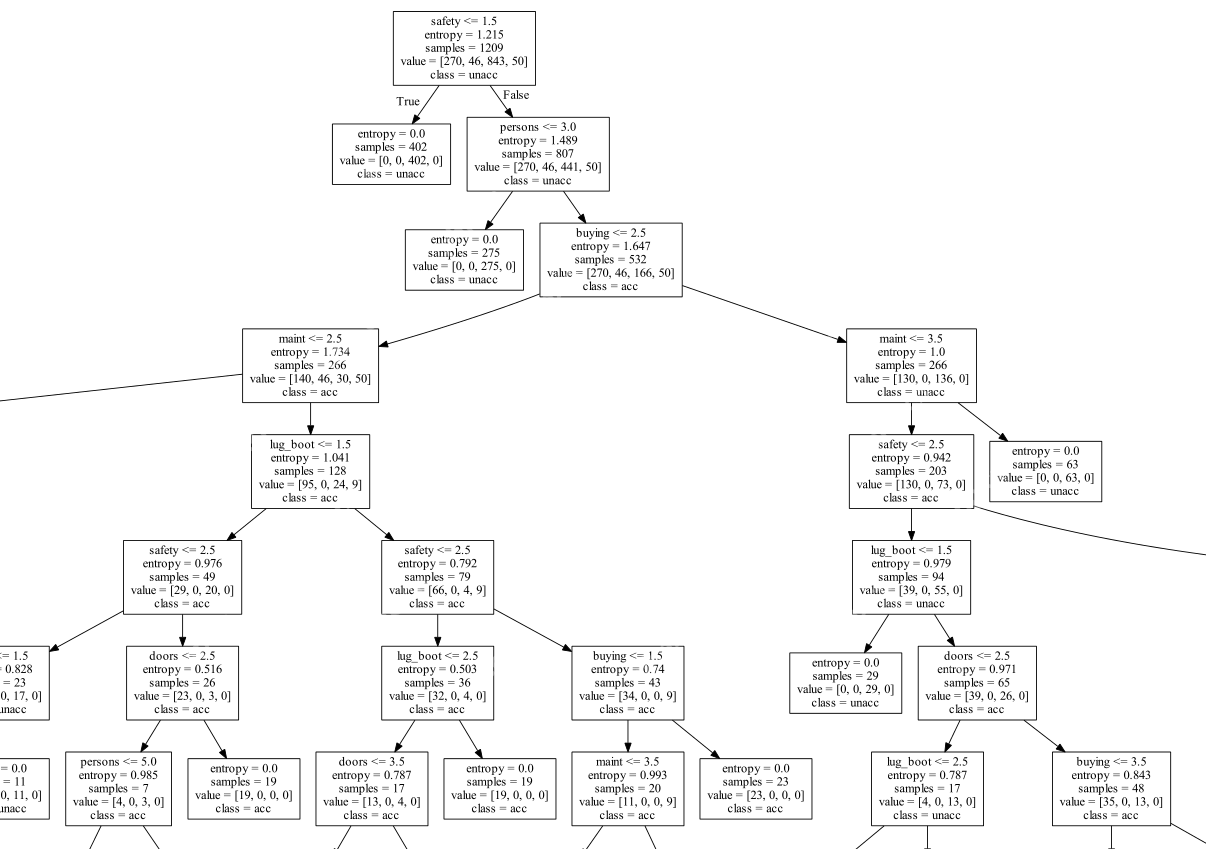
python决策树GraphViz可视化
安装graphviz 从以下链接下载GraphViz:https://www.php.cn/link/bfaa2ace1082af90074d02006690ddb2。 通过命令conda install python-graphviz来安装graphviz的Python库。 生成可视化文件的代码...

如何用Python实现数据挖掘?sklearn入门实例
用 python 做数据挖掘入门并不难,掌握基础工具和流程即可上手。1. 准备环境与数据:安装 python 及 numpy、pandas、scikit-learn 等库,使用自带的鸢尾花数据集;2. 数据预处理:包括标准化、...

如何用Python构建特征工程—sklearn预处理全流程
在机器学习项目中,特征工程是提升模型性能的关键,而sklearn库提供了完整的预处理工具。1. 首先使用pandas加载数据并检查缺失值与数据类型,缺失严重则删除列,少量缺失则填充均值、中位数或标...

Python中如何实现数据归一化?
在python中,数据归一化可以通过min-max归一化和z-score归一化实现:1.min-max归一化使用公式x_norm = (x - x_min) / (x_max - x_min),适用于无异常值的数据;2.z-score归一化使用公式x_norm =...
bootstrap抽样检验非线性关系步骤
要检验两个变量间的非线性关系并验证其稳定性,可使用bootstrap方法,具体步骤如下:1. 拟合包含非线性项的模型,如加入多项式项或使用gam;2. 编写函数用于每次bootstrap抽样中的模型拟合,并...