



排序

如何使用Java实现OCR?Tesseract训练模型
要实现java中的ocr,tesseract是核心工具,通过tess4j调用其引擎,并可训练自定义模型提升识别准确率。具体步骤为:1. 引入tess4j依赖并配置tesseract环境;2. 进行图像预处理、设置参数并执行o...

如何使用Python处理PDF文件?PyPDF2操作指南
pypdf2 是一个用于处理 pdf 文件的 python 库,适合执行提取文本、合并文档、拆分页面等基础操作。要提取文本,可使用 pdfreader 并遍历每页调用 .extract_text();对于合并多个 pdf,可用 pdfw...

Java实现PDF文档生成与编辑的详细技术指南
java项目中生成和编辑pdf的常见方案包括:1.使用itext创建和修改pdf,支持复杂内容但需注意商业授权;2.采用apache pdfbox进行文本提取和轻度编辑;3.通过dynamic-jasper或jasperreports生成报...

如何用BOM实现页面的OCR识别功能?
bom本身不能直接进行ocr识别,因为bom主要负责与浏览器窗口、文档等交互,提供操作浏览器环境的接口,而ocr涉及图像处理和模式识别等复杂算法。解决方案包括引入tesseract.js库,获取图像源,调...

怎样用Python处理PDF文件?PyPDF2使用指南
pypdf2能处理pdf的读取、写入、分割、合并及文本提取,但无法处理复杂格式或扫描版pdf。其常见操作包括:1.安装方法为pip install pypdf2;2.读取pdf需用pdfreader并逐页提取文本;3.写入pdf可...

Python处理网页数据时如何应对反爬?随机延迟与请求伪装
python处理网页数据时,应对反爬的核心思路是模拟真实用户行为。1. 设置合理的随机延迟:通过观察网站访问模式,使用time.sleep()结合random模块生成合理范围的延迟;2. 伪装请求头:修改user-a...

PHP中的Web爬虫:如何抓取网页数据
php实现web爬虫的核心步骤包括发送http请求、解析html内容、数据存储和处理反爬机制。①使用curl库或file_get_contents函数发送http请求获取网页源码,推荐使用功能更强大的curl;②通过正则表...

免费的OCR识别工具就是香!
哈喽,大家好,我是爱撸码的开源大叔! 经常在网上查询文档资料的朋友一定有过这样的经历:好不容易找到了需要的内容,可是别说下载了,连复制一句话都不给复制的。尤其是 PDF 文档和图片类资料...
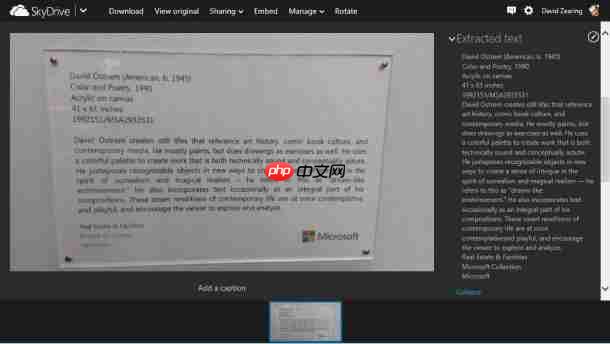
微软为SkyDrive加入OCR光学字符识别功能
光学字符识别(ocr)技术能够将图片中的文字转化为可编辑的文字。尽管该技术至今仍未完全成熟,但在多数情况下已能替代人工操作。微软早在office 2003中就已引入ocr功能。近期,微软为其skydriv...

js如何实现屏幕截图功能 js网页截图的3种实现方法
html2canvas截图模糊可通过提高scale值、启用usecors、调整window尺寸、优化字体和css样式、延迟截图、升级库版本或改用其他方案解决。1.提高scale值可增强清晰度但影响性能;2.启用usecors处理...