



排序

如何使用Python连接Hadoop?PyHDFS配置方法
python连接hadoop可通过pyhdfs库实现,适用于数据分析、etl流程等场景。1. 安装pyhdfs使用pip install pyhdfs;2. 配置连接参数,指定namenode地址和用户名;3. 使用hdfsclient建立连接;4. 执...

Hadoop MapReduce教程:实现(Key, Value列表)输出
本文旨在指导Hadoop MapReduce开发者如何实现将具有相同Key的多个Value合并成一个列表,并以(Key, Value列表)的形式输出。通过示例代码,详细讲解了Reducer中处理Iterable类型Value集合的常见方...

Hadoop Reduce 函数输出 (Key, Value 列表)
本文旨在提供一个清晰的 Hadoop MapReduce 教程,指导开发者如何将 Reduce 函数的输出结果格式化为 (Key, Value 列表) 的形式。通过详细的代码示例和逐步解释,帮助读者理解如何处理 Iterable ...
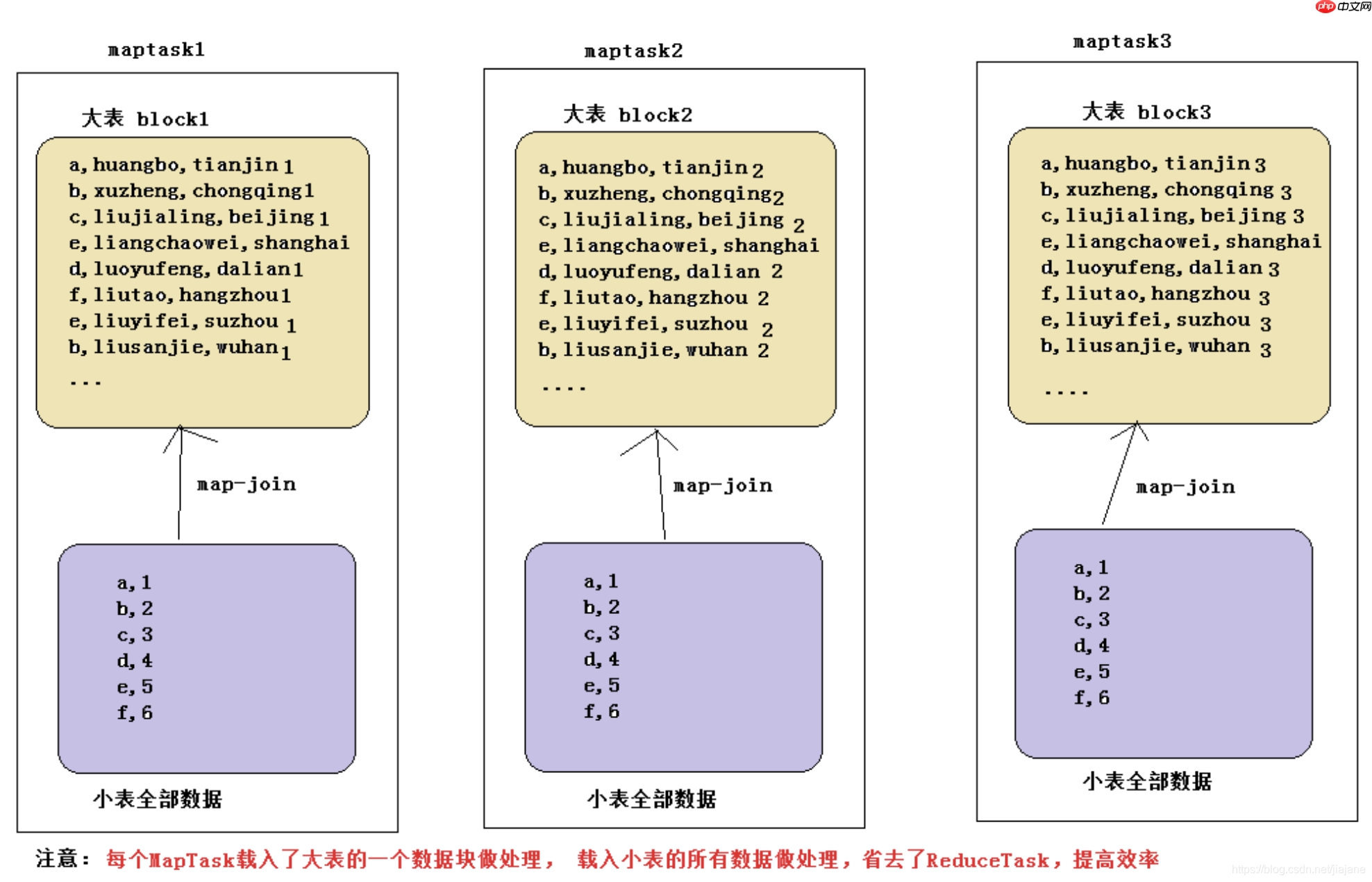
【Hive】hive 数据倾斜、优化策略、hive执行过程、垃圾回收
1. 数据倾斜 1.1 什么是数据倾斜?由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点Hadoop 框架的特性代码语言:txt复制- 不怕数据大,怕数据倾斜- Jobs 数比较多的作业运行效率...

CentOS HDFS如何配置优化性能
在centos系统中配置并优化hadoop分布式文件系统(hdfs)的性能是一项复杂的任务,涉及多个层面的调整。以下是一些核心步骤和建议: 硬件选型 采用高速存储设备:如SSD,以显著提升I/O吞吐能力。...
HBase数据迁移在CentOS如何操作
在centos上进行hbase数据迁移可以通过以下几种方法操作: 使用HBase快照功能 创建快照:首先,在源HBase集群上创建一个快照。hbase(main):0 snapshot 'snapshot_name' 导出快照:然后,将快照导...
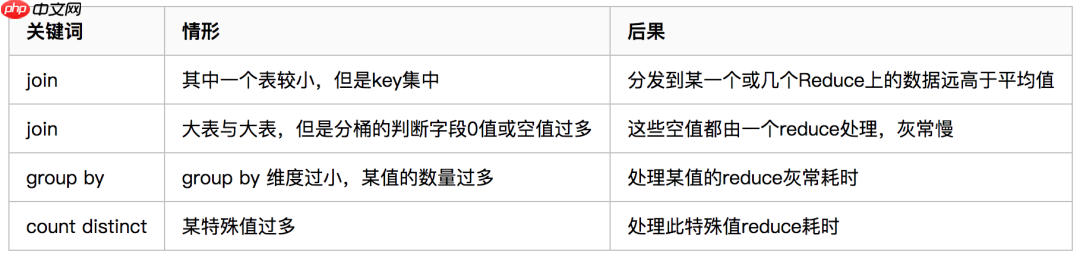
万文Hive常用参数调优及优化(建议收藏)
1. limit限制调整 一般情况下,Limit语句还是需要执行整个查询语句,然后再返回部分结果。 有一个配置属性可以开启,避免这种情况---对数据源进行抽样。 hive.limit.optimize.enable=true --- ...
CentOS HDFS数据备份与恢复方法
在centos系统里,hdfs(hadoop 分布式文件系统)的数据备份与恢复对于保障数据的安全性与可靠性至关重要。以下是一些常用的备份与恢复策略: HDFS 快照(Snapshot) 建立快照: hdfs dfsadmin -...
CentOS HDFS资源管理如何配置
centos系统上hadoop分布式文件系统(hdfs)的资源管理配置详解 本文档详细介绍如何在CentOS系统上配置Hadoop分布式文件系统(HDFS),涵盖Hadoop安装、环境变量设置、配置文件修改、服务启动以及HDF...
怎样检查CentOS HDFS状态
要在centos上检查hdfs(hadoop分布式文件系统)的状态,可以采用以下几种方法: 命令行工具: 使用hdfs dfsadmin命令来获取HDFS的状态信息。例如:hdfs dfsadmin -report此命令将显示HDFS集群的...