



排序

Sublime编写异步爬虫脚本流程演示_适合分布式爬虫与数据采集任务
异步爬虫适合处理大量请求,sublime适合编写此类脚本。1. 安装aiohttp和beautifulsoup4库用于异步请求与html解析;2. 使用asyncio、aiohttp和beautifulsoup构建并发抓取页面并解析标题的基本结...
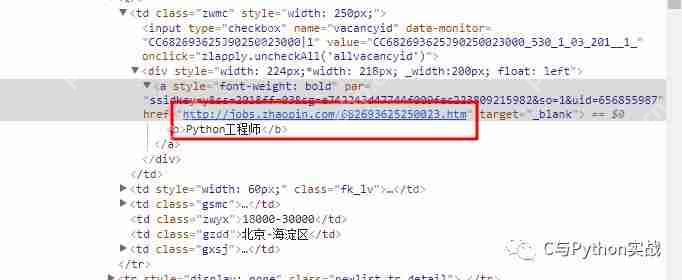
Python爬虫之六:智联招聘进阶版
运行平台: windows python版本: python3.6 ide: sublime text 其他工具: chrome浏览器0、写在前面的话本文是基于基础版上做的修改,如果没有阅读基础版,请移步 Python爬虫之五:抓取智联招...

怎么用python爬取网站
本文将详细介绍如何使用python来抓取网站内容,希望能给大家带来实用的参考,助您在学习后有所收获。 Python抓取网站的步骤指南 1. 选用合适的工具库 BeautifulSoup:用于解析HTML和XML文档 Req...

Python源码解析影视剧时间线关系 结构化抽取剧情的Python源码方案
要从影视剧的python源码中解析时间线关系并结构化抽取剧情,首先需分析源码结构,识别时间信息、事件描述和角色定义;其次,针对不同格式使用字符串处理、正则表达式或nlp技术提取信息;接着,...

高效网页数据抓取:利用JSON API获取动态分页数据
传统网页抓取工具在处理动态加载内容时常遇瓶颈。本教程揭示了一种更高效、稳定的数据获取策略:通过识别并直接调用网站后台的JSON API接口,可以轻松获取完整的分页数据,避免复杂的HTML解析和...

Python中如何获取网页的HTML内容?
在python中获取网页的html内容可以使用requests库。具体步骤包括:1. 使用requests.get()发送get请求获取html内容;2. 检查http状态码,处理错误情况;3. 设置用户代理和请求超时;4. 使用beaut...

xml格式的网页怎么解析 简单几步教你解析网页中的xml格式数据
解析xml网页的关键在于确认格式、选择工具、掌握步骤。首先要确认网页是标准xml格式,可通过文件后缀.xml、浏览器显示结构化标签或响应头content-type判断;其次根据编程语言选择合适的解析库,...

Python源码抓取在线视频信息 自动化提取视频信息的Python源码方法
python结合yt-dlp库可高效抓取在线视频元数据。1. 安装yt-dlp:使用pip install yt-dlp命令安装;2. 导入并配置:通过设置simulate=true和download=false参数仅提取信息;3. 调用api:使用extra...