



排序

Python如何实现智能推荐?知识图谱应用
python实现智能推荐结合知识图谱的核心在于构建用户、物品及其复杂关系的知识网络,并通过图算法和图神经网络提升推荐效果。1. 数据获取与知识图谱构建是基础,需从多源数据中抽取实体和关系,...

如何用Python开发网络爬虫?aiohttp异步方案
aiohttp适合高效率并发爬虫开发因为它基于异步io能处理大量请求。相比requests同步方式效率低,aiohttp配合async/await实现异步请求,适合大规模抓取任务。使用时需导入aiohttp和asyncio模块,...

如何使用正则表达式提取HTML中的特定内容?
正则表达式可用于提取html中的特定内容,但并非最佳工具,推荐使用beautifulsoup等库。1. 提取标签内文本可用类似 (.*?)的正则,捕获组提取所需内容;2. 提取属性值如图片src可用,并可通过src=...

HTML转换成DOCX文件的方法
使用python的python-docx和beautifulsoup库可以实现html到docx的转换。1) 使用beautifulsoup解析html内容。2) 利用python-docx生成和操作docx文件。3) 遍历html元素并添加到docx文档中。4) 保存...

如何转换HTML为JSON?数据提取简易教程
将html转换为json需解析文档、提取数据并结构化输出。1.选择合适的解析工具,如python的beautiful soup或javascript的cheerio;2.加载html文档内容;3.使用css选择器或xpath定位目标元素;4.提...

Python爬取数据存入MySQL的方法是什么
本文将详细介绍如何使用Python从网络中获取数据并将其存储到MySQL数据库中。希望通过本文的分享,能为大家提供有用的参考,帮助大家在数据处理方面有所收获。 Python爬取数据并存储到MySQL数据...

Python爬虫技术入门教程 Python爬虫基础知识点有哪些
学python爬虫的关键在于掌握核心基础并动手实践。1. 首先要了解http请求与响应机制,包括get/post方法、headers作用及常见状态码,使用requests库发送请求获取数据;2. 掌握html结构解析,利用b...
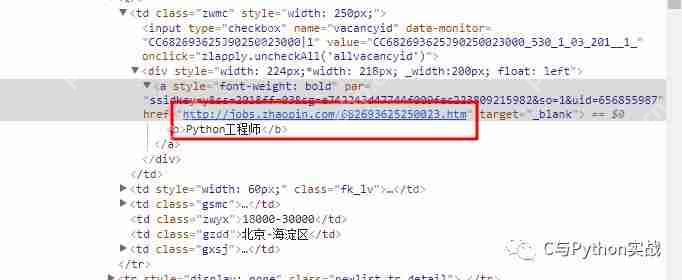
Python爬虫之六:智联招聘进阶版
运行平台: windows python版本: python3.6 ide: sublime text 其他工具: chrome浏览器0、写在前面的话本文是基于基础版上做的修改,如果没有阅读基础版,请移步 Python爬虫之五:抓取智联招...

如何在Debian上优化Python SEO
在Debian系统上优化Python SEO可以涵盖多个层面,包括代码性能提升、选用适当的库与工具,以及配置开发环境等。尽管提供的搜索结果没有直接提及Python SEO优化的具体方法,但它们确实提供了有关...

使用BeautifulSoup高效查找HTML元素:解决注释与CSS类选择难题
本文旨在解决使用BeautifulSoup进行网页抓取时,遇到目标HTML元素被注释或CSS类选择器使用不当导致无法正确查找的问题。文章将详细阐述如何通过预处理移除HTML注释、正确使用find_all方法的clas...