



排序
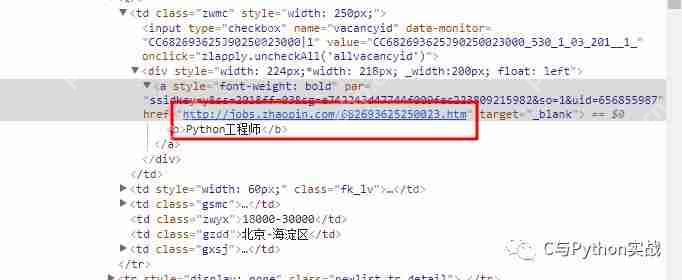
Python爬虫之六:智联招聘进阶版
运行平台: windows python版本: python3.6 ide: sublime text 其他工具: chrome浏览器0、写在前面的话本文是基于基础版上做的修改,如果没有阅读基础版,请移步 Python爬虫之五:抓取智联招...

Python人马兽系列是啥 Python人马兽系系列主要内容有哪些
“Python 人马兽系列”没有确切定义,可能与神话、游戏、库戏称、教育资源或拼写错误有关。以下是可能相关的Python库:1. NumPy/SciPy用于科学计算,2. Matplotlib/Seaborn用于数据可视化,3. S...

python爬虫需要学哪些东西 爬虫必备知识清单
要成为python爬虫高手,你需要掌握以下关键技能和知识:1. python基础,包括基本语法、数据结构、文件操作;2. 网络知识,如http协议、html、css;3. 数据解析,使用beautifulsoup、lxml等库;4...

Python中如何模拟浏览器操作?
在python中模拟浏览器操作主要使用selenium和beautifulsoup。1.安装selenium:pip install selenium。2.选择并配置浏览器驱动程序,如chromedriver。3.使用selenium启动浏览器并访问网页。4.模...

Python中如何获取网页的HTML内容?
在python中获取网页的html内容可以使用requests库。具体步骤包括:1. 使用requests.get()发送get请求获取html内容;2. 检查http状态码,处理错误情况;3. 设置用户代理和请求超时;4. 使用beaut...

Python中怎样实现Web爬虫?
用python实现web爬虫可以通过以下步骤:1. 使用requests库发送http请求获取网页内容。2. 利用beautifulsoup或lxml解析html提取信息。3. 借助scrapy框架实现更复杂的爬虫任务,包括分布式爬虫和...

Python中如何爬取网页数据?
使用 python 爬取网页数据的方法包括:1) 使用 requests 和 beautifulsoup 库进行基本爬取,2) 设置 user-agent 头应对反爬虫机制,3) 使用 selenium 处理动态加载内容,4) 采用异步编程提高爬...

Python中怎样解析XML文件?
在python中解析xml文件可以使用标准库的xml.etree.elementtree或第三方库lxml。1. 使用xml.etree.elementtree解析xml文件,如et.parse('example.xml')并遍历节点。2. 使用lxml解析xml文件,如et...

Python中怎样定义爬虫规则?
在python中定义爬虫规则可以通过使用scrapy、beautifulsoup或requests+正则表达式等工具来实现。1. 使用scrapy的spider类定义基本规则,如遍历链接和提取内容。2. 深入理解目标网站结构,提高爬...

Python中如何遍历DOM树?
在python中,遍历dom树是为了解析和操作文档元素。使用beautifulsoup库,可以通过递归或迭代方法遍历dom树:1)递归方法直观但可能导致栈溢出;2)迭代方法高效,避免栈溢出。完整句子结束。 在Py...